.png)
Modern storage drives have a feature called SMART data, which stands for Self-Monitoring, Analysis, and Reporting Technology. This feature is intended to monitor the health of your data drive and provide an early warning if your SSD or HDD is suffering from problems or has reached the end of its useful life cycle.
While an incredibly useful tool for diagnosing the health and safety of your drives, there are some quirks to the SMART reporting system that could lead to you misdiagnosing an issue. So before you get ready to recycle your old drive, make sure you do a full sanity check on these parameters.
Read/Write Data
Does it seem reasonable?
Before accepting that "Failed" SMART reading, check the read/write values of your drive on the report. If you've got a 512GB SSD that supposedly read and wrote several terabytes of data, there may be something else going on with your drive. This could be caused by insufficient RAM for your workload. If your system runs out of memory, it will continuously move data from RAM to storage to free up more memory, which results in a high amount of data being written to the storage drive.
You should also check the Read/Write Error Rates listed in your SMART report. You'll want to check this with the first-party diagnostic tool provided by your SSD manufacturer to ensure these are within acceptable parameters. It can be hard to tell what is an acceptable threshold for Read/Write Error rates on a third-party SMART report software.
Retired NAND Blocks/Reallocated Sectors
How much of your storage is "retired"?

SMART data will track the number of NAND blocks on your SSD, and when NAND data blocks become unusable, they become "retired" by the storage controller. NAND blocks can become unusable due to wear, data retention issues, failure to erase a block while deleting data or moving data during garbage collection. Similarly, HDDs will reallocate unusable sectors due to wear and data retention issues.
The more retired blocks or reallocated sectors your drive has, the less usable storage space you have. While a small number of retired NAND blocks or reallocated sectors is expected as your drive ages, a high number or steady increase in retired blocks or reallocated sectors could indicate a drive failure. This could also be caused by a reporting error in your SMART data, particularly if you're using a third-party diagnostic tool.
If you're seeing a high number of retired NAND blocks or reallocated sectors, you should sanity check this with a first-party diagnostic tool in addition to third-party utilities like CrystalDiskInfo.
Command Timeout
How quick is your drive?

Command Timeout is more commonly found on hard disk drives rather than solid state storage. Command Timeout indicates the number of operations aborted due to HDD timeout. You want this value to be at zero, so if you have a number greater or equal to 1 under Command Timeout, you may want to replace the drive.
Because this is a critical parameter, you'll want to make sure you double-check the Command Timeout before completely trashing the drive, but if this is showing on the SMART report of your HDD manufacturer's diagnostic tool, chances are you have a failing drive. You might still be able to get some use out of it before the drive fully fails, but definitely have backups and a replacement drive on hand if you ever see this value above zero.
Unsafe Shutdown/ Unexpected Power Loss
BSOD is also bad for a storage drive
While the infamous Blue Screen of Death is generally bad for your PC overall, SSDs and HDDs take damage from repeated, unexpected shutdowns.
Under normal shutdown circumstances, your computer sends a message to the SSD or HDD that power is about to go down, which allows the drive to complete any ongoing activity. The drive acknowledges the shutdown message to the host computer, and then turns off your system. In a situation where the power goes down unexpectedly, this can cause issues with the drive's file system, which can cause data loss over time.
If you have a high number of unexpected shutdowns, this could indicate a problem with your PSU or power connections on your PC. You'll also want to double-check the health of your drive if you notice a high number of unexpected power loss incidents, as repeated occurrences can cause data storage issues.
Temperature
NVMe flash memory runs hot, but not that hot

NVMe M.2 SSDs run hotter than HDD or SATA SDD drives, but you shouldn't be seeing temperatures above 50˚C with the drive idling, and it shouldn't exceed 70˚C under load. If you're consistently seeing temperatures run above 70˚C, you'll want to check your cooling and ventilation systems, and perhaps opt for a heat-sink.
If you're worried your SMART temps are inaccurate, you should also look at the temperatures of other components inside your PC case to see if this is a problem with your overall build.
Spin Retry Count
A slow drive could indicate failure
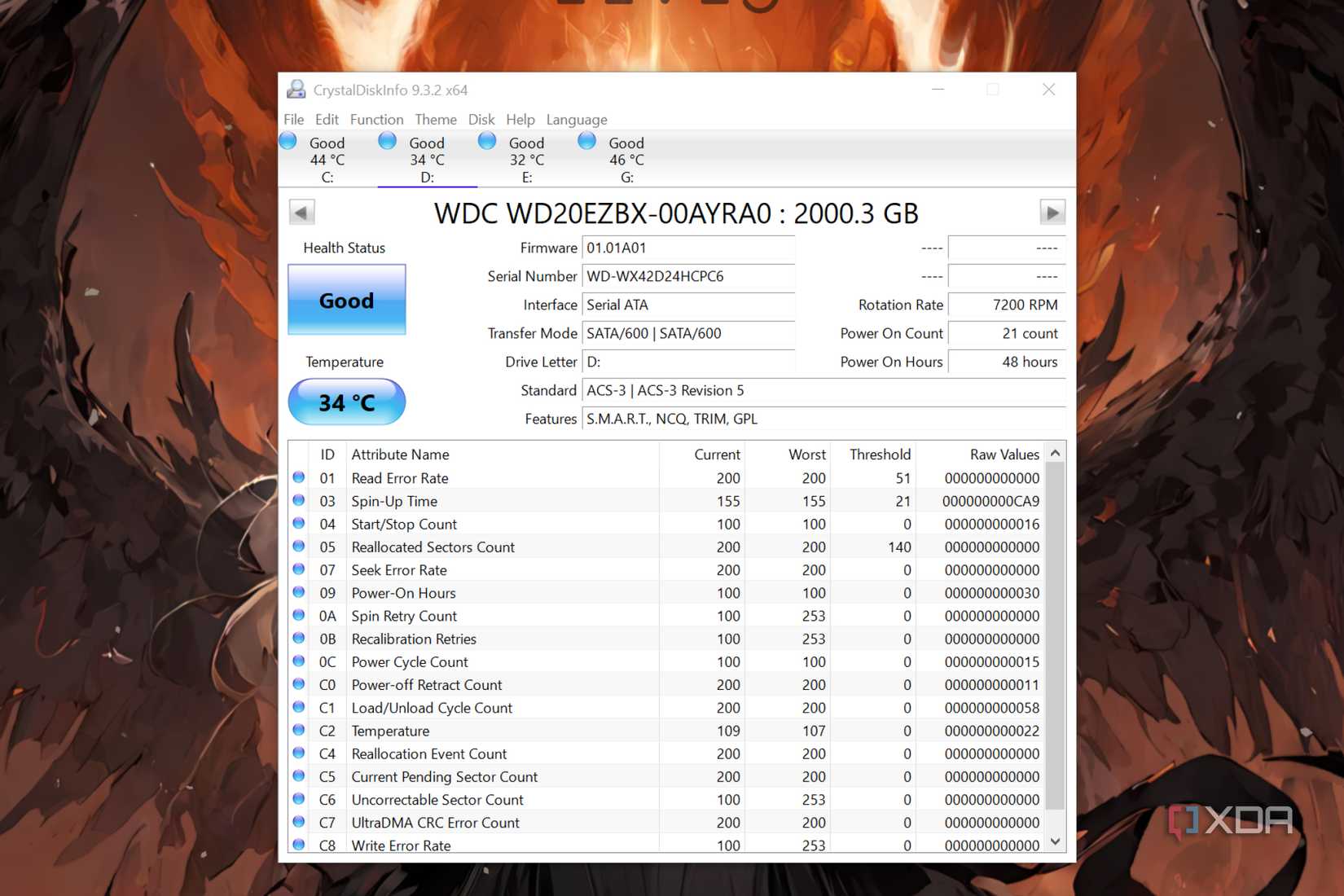
Tracking how long it takes your HDD to boot can be a good indicator of drive health. If you've got a long startup time, this could indicate a failing drive or a mechanical issue. If your SMART report indicates a high number in spin retry count, or a steady rise in this value, it's likely a sign of drive failure. But if you have a quick boot time and a high spin retry count, it could be a data reporting error.
Sometimes it's failure, sometimes it's bad software
To ensure your SMART data is as accurate as possible, it's recommended to use the first-party tools provided by your SSD or HDD manufacturer. While you may prefer third party tools for ease of use or because they're multipurpose, third-party tools may not have all the information needed to accurately assess the health of your storage drive.
Thus, the sanity check. Always try and verify the data with additional tools. You should also keep your storage drive backed up with either a local backup or a cloud backup service (or better yet, even both for a 3-2-1 backup setup). This way, if you do have a critical drive failure, you won't be losing any of your data.










 English (US) ·
English (US) ·